


Most AI tools forget you the moment the conversation ends. You upload a document, ask a question, get an answer — and the next time you log in, you're starting over. Every session is a fresh amnesia.
Today we're launching Preppr Knowledge — a persistent memory layer that sits underneath Ask Preppr, Exercise Designer V2, and every other tool in the platform. It holds your doctrine, your plans, your organization's context, and (increasingly) the work you've done with Preppr itself. It's what turns a chat assistant into a genuine thinking partner for preparedness.
This post explains what Preppr Knowledge is at launch, how it makes the rest of the platform work, and where it's heading.
What Preppr Knowledge is
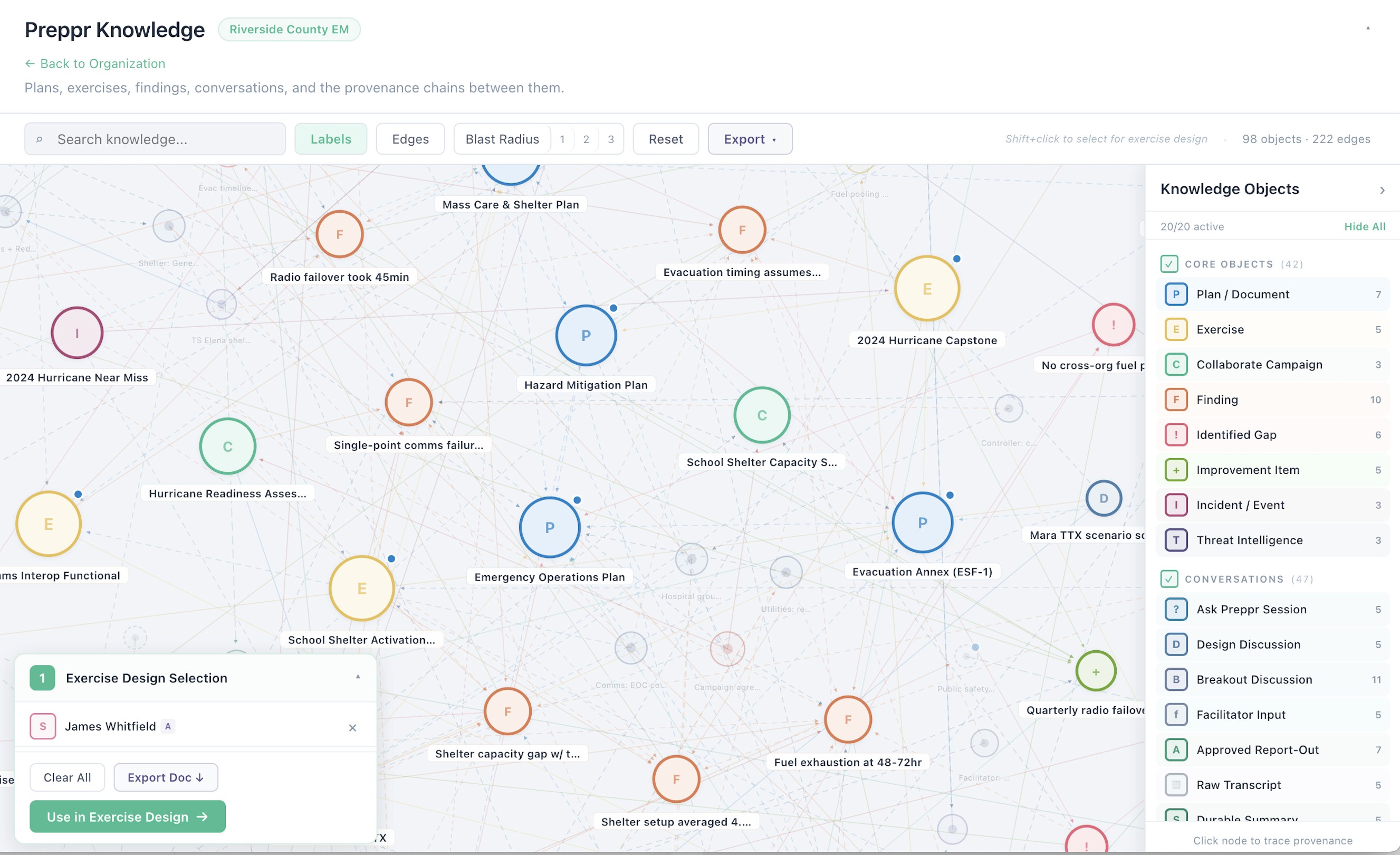
Preppr Knowledge is a structured model of your organization's preparedness posture. Documents are one kind of object inside it. Your jurisdiction, your hazards, your capabilities, your frameworks, your lessons learned, your resources — each of these is a distinct kind of object too. Over time, so are your exercises, your AARs, your improvement actions, your collaborators, and the reasoning you've worked through in past sessions.
This is a meaningful departure from how most AI tools handle knowledge. The common pattern — sometimes called retrieval-augmented generation — treats your library as a pile of text to be searched: chunk it up, find the passages that match a query, hand them to the model. That works for answering questions against documents, and Preppr Knowledge does it well. But documents are only one kind of thing your organization knows, and "similar text" is only one kind of relationship that matters.
A jurisdiction has hazards. Hazards map to capabilities. Capabilities get exercised. Exercises produce AARs. AARs generate improvement actions. Improvement actions have owners. Plans cite doctrine. Doctrine has versions. None of those relationships are text-similarity relationships, and none of them survive a chunking-and-embedding pipeline alone.
Preppr Knowledge is built to hold the objects and the relationships. When you upload a document, yes — it gets parsed, enriched, and made searchable. But it also gets situated: connected to the plan it supports, the capabilities it addresses, the jurisdiction it applies to, the doctrine it references. The same is true of your profile data, your exercise outputs, and (increasingly) everything else Preppr captures.
The result is a knowledge base that doesn't just answer "what does this document say?" It answers "what does my organization know, how does it fit together, and what does it imply for the work in front of me?"
And you don't start from an empty library. Every Preppr Knowledge base ships pre-loaded with the national doctrine corpus — CPG 101, HSEEP, NIMS, the National Response Framework, the National Preparedness Goal, the Core Capabilities, ESF annexes, PHEP and HPP guidance, and the rest of the federal preparedness foundation. You don't have to upload it, maintain it, or hunt down the right version. It's already there, already structured, and already available to every tool in the platform. Your uploads layer your jurisdiction's specifics on top of a foundation the whole field shares.
The practical effect: every question you ask, every exercise you design, every assessment you run has access to the totality of what your organization knows — as a connected whole, not just as a pile of files.
What doesn't flow into your knowledge base
Just as important as what Preppr Knowledge captures is what it deliberately leaves out. Documents you attach to a single Ask Preppr session — a one-off draft, a reference you want to ask a quick question about, a file someone sent you to glance at — stay in that session as transient content. They're available to Preppr while you're working, but they don't get absorbed into your permanent knowledge base.
This is intentional. A knowledge base is only useful if it reflects what your organization actually stands behind. If every draft, every working document, and every "take a look at this" attachment got permanently mixed in with your approved doctrine, the signal-to-noise ratio would collapse fast. You'd end up with a library where an early-draft scenario sits next to your official EOP, and Preppr couldn't tell the difference.
Keeping session attachments transient keeps your knowledge base clean. When something is ready to be part of your organization's permanent memory, you upload it deliberately. Until then, it lives where it belongs — in the session where you're working on it.
How it powers Ask Preppr
When you ask Ask Preppr a question, it doesn't just look at the document in front of you. It searches across your entire knowledge base — every doctrine document, every plan, every after-action report, every reference you've ever uploaded — and pulls the specific passages that matter for your question.
You see those passages cited directly in the answer. Every citation is clickable and opens to the exact section of the source document. Nothing is hallucinated; nothing is hidden. When Ask Preppr tells you what a plan requires or what a framework specifies, it's because Preppr Knowledge found it and showed you where it came from.
This is what makes Ask Preppr feel different from a generic chatbot. It isn't reasoning from a training-data approximation of what an emergency plan might say. It's reasoning from your knowledge base.
How it powers Exercise Designer V2
Exercise Designer V2 leans on Preppr Knowledge in a different way. When you design an exercise, Preppr needs to ground the scenario in real doctrine, real capabilities, and real objectives. The knowledge base is where it gets that grounding.
If you ask for a tabletop exercise anchored state all-hazards plan and THIRA, Preppr Knowledge surfaces the relevant sections. If you're working an HSEEP-aligned exercise against specific core capabilities in our multi-year training plan, the knowledge base makes those capabilities available to the design process. Your previous exercises, your AARs, your improvement plans — all of it is available as raw material for the next exercise you build.
The practical effect is that exercises stop being generic templates with your logo on top. They become documents that reflect what your jurisdiction actually faces, what your team has actually learned, and what your doctrine actually requires.
Why this matters
There's a pattern we see across the emergency management and public health field: organizations accumulate enormous amounts of knowledge — plans, AARs, SOPs, training materials, lessons from real incidents — and most of it sits unread on a shared drive. It's technically available, but practically inert. When a decision needs to be made or an exercise needs to be designed, nobody has time to dig through years of documents to find the piece that matters.
Preppr Knowledge is the answer to that problem. Your library stops being a graveyard and starts being a working memory. Everything you've learned is active, searchable, and automatically brought to bear on whatever you're doing right now.
This is the real shift from "AI chatbot" to "AI-native platform." A chatbot reads what you paste into it. A platform reads your organization.
Where it's heading
At launch, Preppr Knowledge holds documents, profile data, and the national doctrine corpus — connected through the relationships Preppr can infer from that material. The roadmap expands what counts as a knowledge object, and the direction matters.
Session conversations become knowledge objects. Right now, the work you do in Ask Preppr — the analysis you refine, the positions you work out, the decisions you arrive at — lives inside individual chat sessions. That's about to change. Your sessions will become first-class objects in Preppr Knowledge, connected to the documents they referenced, the plans they informed, and the decisions they supported. The thinking you did last month will be available to inform the work you're doing today. Preppr won't just remember your documents; it'll remember your reasoning, and know how that reasoning connects to everything else.
Collaborators and reviewers become first-class knowledge. Preparedness is a team sport. The people who contributed to a plan, who reviewed an AAR, who signed off on an improvement action — these relationships matter. Preppr Knowledge will capture them as objects in the graph, so when you ask "who has weighed in on our mass casualty plan" or "which of our reviewers has flagged concerns about this scenario," you'll get an answer grounded in your actual working relationships.
The graph deepens. As more object types come online — exercises, AARs, improvement actions, capabilities, threats, jurisdictions, resources, people — the relationships between them get richer. Preppr will be able to trace a lesson learned in 2023 forward through every plan revision, exercise, and policy change it influenced. It'll tell you which capabilities your last three exercises have and haven't touched. It'll answer questions like "show me every part of our preparedness posture that depends on a resource we flagged as at-risk six months ago" — questions that are impossible to answer against a pile of documents but straightforward against a connected model of your organization.
The substrate, not the surface
There's a tendency in this industry to treat AI as a surface feature — a chat window bolted onto existing software. Preppr was built on the opposite premise: the AI is only as good as the knowledge it operates on, and knowledge is only useful when it's structured, connected, and alive.
Preppr Knowledge is that substrate. It's what makes Ask Preppr's answers trustworthy. It's what makes Exercise Designer V2's exercises real. And as it grows — from documents, to conversations, to collaborators, to a full relational graph of your preparedness posture — it's what will let Preppr do work that no document pile, no chatbot, and no bolted-on AI feature can touch.
The work of preparedness is the work of building, maintaining, and drawing on institutional knowledge. Preppr Knowledge is built to do exactly that.
Available now
Preppr Knowledge is live today in every Preppr Basic and Pro account at no additional cost. If you're already a subscriber, it's already working — every document you've uploaded and every profile field you've filled out is flowing into it automatically. The expansions described above — session-level memory, collaborator and reviewer knowledge, and the full relational knowledge graph — will roll out progressively over the coming releases.
Not a subscriber yet? Grab a 14-day, all access, free trial.


